本文摘要 DeepSeek
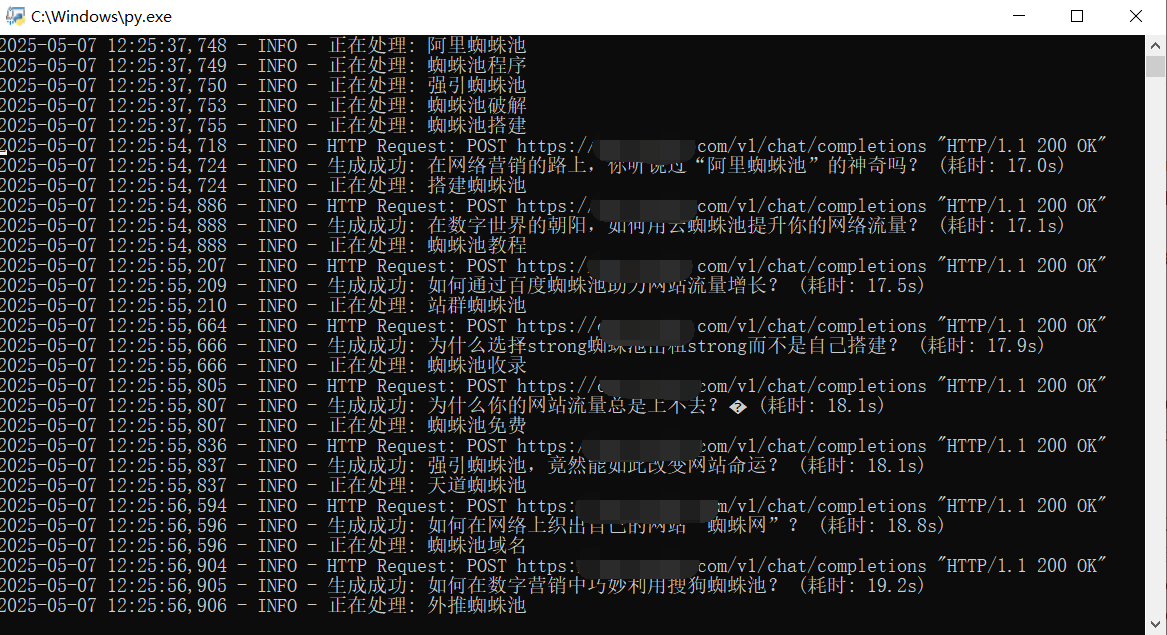
本文介绍了一种使用Python将本地文本内容高效上传至小旋风蜘蛛池的方法。核心代码通过多线程并发处理,自动读取指定目录下的txt文件,提取文件名作为标题,内容作为正文,通过POST请求提交到小旋风接口。代码包含异常处理、去重机制,并支持20线程并发上传,最后统计发布总数。该方法适用于批量处理AI生成或采集的本地数据,提升入库效率。
写这个代码的原因
随着越多越多的采集方式和AI生成内容的普及,很多本地数据想要上传到小旋风蜘蛛池怎么办?今天教你一个python高效入库的方法。
核心代码
import requests
import glob
import os
from concurrent.futures import ThreadPoolExecutor
files = glob.glob('./文章/*.txt')
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
}
def postxxf(f):
with open(f,"rb") as fd:
content = fd.read().decode("utf-8")
title = os.path.basename(f).split(".")[0]
try:
rsp = requests.post("你的小旋风发布接口", timeout=30, headers=HEADERS, data={"title": title, "body": content})
print("正在发布:", title)
print(rsp.json()["msg"])
except Exception as e:
print("小旋风发布出错", e)
if __name__ == "__main__":
published_titles = set()
publish_count = 0
with ThreadPoolExecutor(max_workers=20) as tdp:
for f in files:
title = os.path.basename(f).split(".")[0]
if title in published_titles:
print("已发布:", title)
continue
tdp.submit(postxxf, f)
published_titles.add(title)
publish_count += 1
tdp.shutdown(wait=True)
print("发布总数:", publish_count)